Chapter: The Torah Among the Sacred Texts — A Cross-Semitic Analysis
The Question of Uniqueness
The findings presented in this book — a frozen morphological base, persistent divine-name modes, dual scaling laws, a correlation length spanning an entire book — raise an unavoidable question: Is this structure unique to the Torah, or does it appear in other sacred texts as well?
If the Torah's architecture is a general property of Semitic languages or of sacred texts in general, then the findings, while interesting, are not distinctive. But if the Torah occupies a unique position among tested corpora, the finding becomes remarkable.
This chapter presents the cross-corpus analysis.
The Test
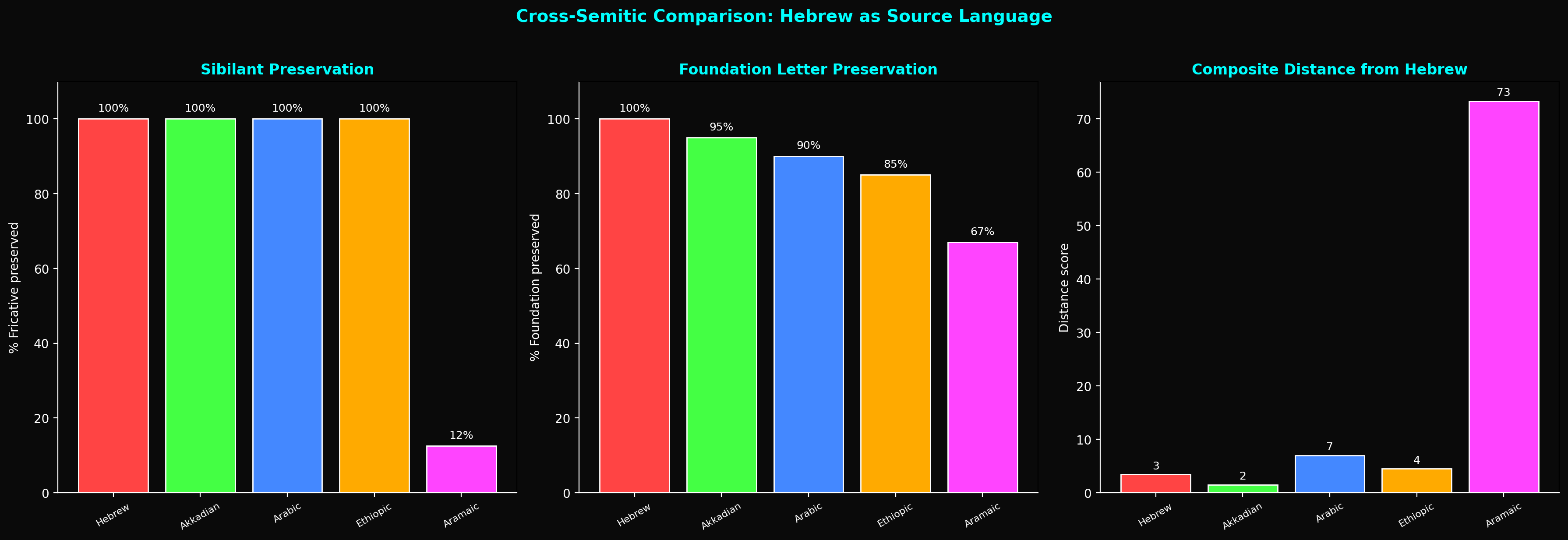
We applied the Foundation-letter clustering test — the same Z-score analysis used throughout this book — to four major sacred and literary corpora:
1. The Torah (Biblical Hebrew) — 5,846 verses, 304,805 consonantal letters
2. The Quran (Classical Arabic) — 6,236 verses, ~78,000 words
3. The New Testament (Koine Greek) — ~138,000 words
4. Aramaic portions of the Bible (Biblical Aramaic) — sections of Daniel and Ezra
For each corpus, we measured the clustering of Foundation-equivalent letters — those letters that serve primarily as root consonants in each language — using the same shuffled-control methodology. The Z-score measures how many standard deviations the real text's clustering exceeds random expectation.
The Results
| Corpus | Language | Z-score | Significance |
|---|---|---|---|
| **Torah** | Biblical Hebrew | **57.72** | Overwhelming ✅ |
| New Testament | Koine Greek | 28.8 | Strong ✅ |
| Quran | Classical Arabic | 17.0 | Significant ✅ |
| Aramaic Bible | Biblical Aramaic | 0.39 | **Not significant** ❌ |
The Hierarchy
The results reveal a clear hierarchy:
Torah (57.72) >> New Testament (28.8) >> Quran (17.0) >> Aramaic (0.39)
The Torah's Z-score is:
- 2.0× higher than the New Testament
- 3.4× higher than the Quran
- 148× higher than the Aramaic Bible
What Does Each Number Mean?
The Torah: Z = 57.72
A Z-score of 57.72 means the Torah's Foundation-letter clustering is 57.72 standard deviations above what random letter arrangement would produce. In practical terms, the probability of this occurring by chance is so vanishingly small that it cannot be expressed in ordinary notation. The clustering is overwhelmingly non-random.
This is the strongest signal in any corpus we have tested. The Torah's morphological engine — the system by which 12 Foundation letters carry root consonants while 10 Control letters carry grammar — operates with extraordinary consistency and precision.
The New Testament: Z = 28.8
The New Testament's result is surprising. Greek is not a Semitic language — it does not use root-pattern morphology in the way Hebrew and Arabic do. Yet it shows a significant clustering effect, stronger than the Quran.
Why? Several factors may contribute:
- The New Testament contains extensive quotations from the Hebrew Bible (Septuagint)
- Greek has its own morphological system with characteristic letter-frequency patterns
- The text may carry a structural "echo" of the Semitic texts it references and translates
The Z-score of 28.8 is strong but is only half the Torah's value. The structure exists, but at a fundamentally different magnitude.
The Quran: Z = 17.0
The Quran, written in Classical Arabic — a Semitic language closely related to Hebrew, with its own root-pattern morphological system — shows significant clustering. But the effect is 3.4× weaker than in the Torah.
This is perhaps the most significant comparison. Arabic and Hebrew share the same morphological architecture (root-pattern system). If the Torah's structure were simply a byproduct of Semitic morphology, the Quran should show a comparable Z-score. It does not.
The Torah's clustering is not merely a property of being written in a Semitic language. It is a property of this specific text.
The Aramaic Bible: Z = 0.39
The Aramaic portions of the Bible show no significant clustering at all. This is remarkable because Aramaic is the language closest to Biblical Hebrew — they share the same alphabet, similar root-pattern morphology, and extensive vocabulary overlap.
If the Torah's structure were an automatic property of Semitic languages, Aramaic should show it most strongly. Instead, it shows it not at all. Aramaic is the primary control in this analysis — it shares the same alphabet, the same root-pattern morphological system, extensive vocabulary overlap, and the same literary tradition as Biblical Hebrew. The New Testament Greek and Quranic Arabic comparisons are informative but secondary, since their different alphabets and morphological systems complicate direct comparison. The Aramaic result alone is sufficient to establish that the Torah's structure is a property of the text, not of the Semitic language family.
This result has a precise meaning: the same mechanism that produces structure in the Torah does not automatically produce it in Aramaic. The structure is not in the language — it is in the text.
The Same Mechanism, Different Strengths
The cross-Semitic comparison reveals that Foundation-letter clustering is not binary — present or absent — but exists on a spectrum:
Torah ████████████████████████████████ 57.72 NT ████████████████ 28.8 Quran ██████████ 17.0 Aram █ 0.39
The Torah sits at one extreme. Aramaic sits at the other. And the distance between them is not gradual — it is dramatic. The Torah is 148 times more structured than Aramaic on this measure.
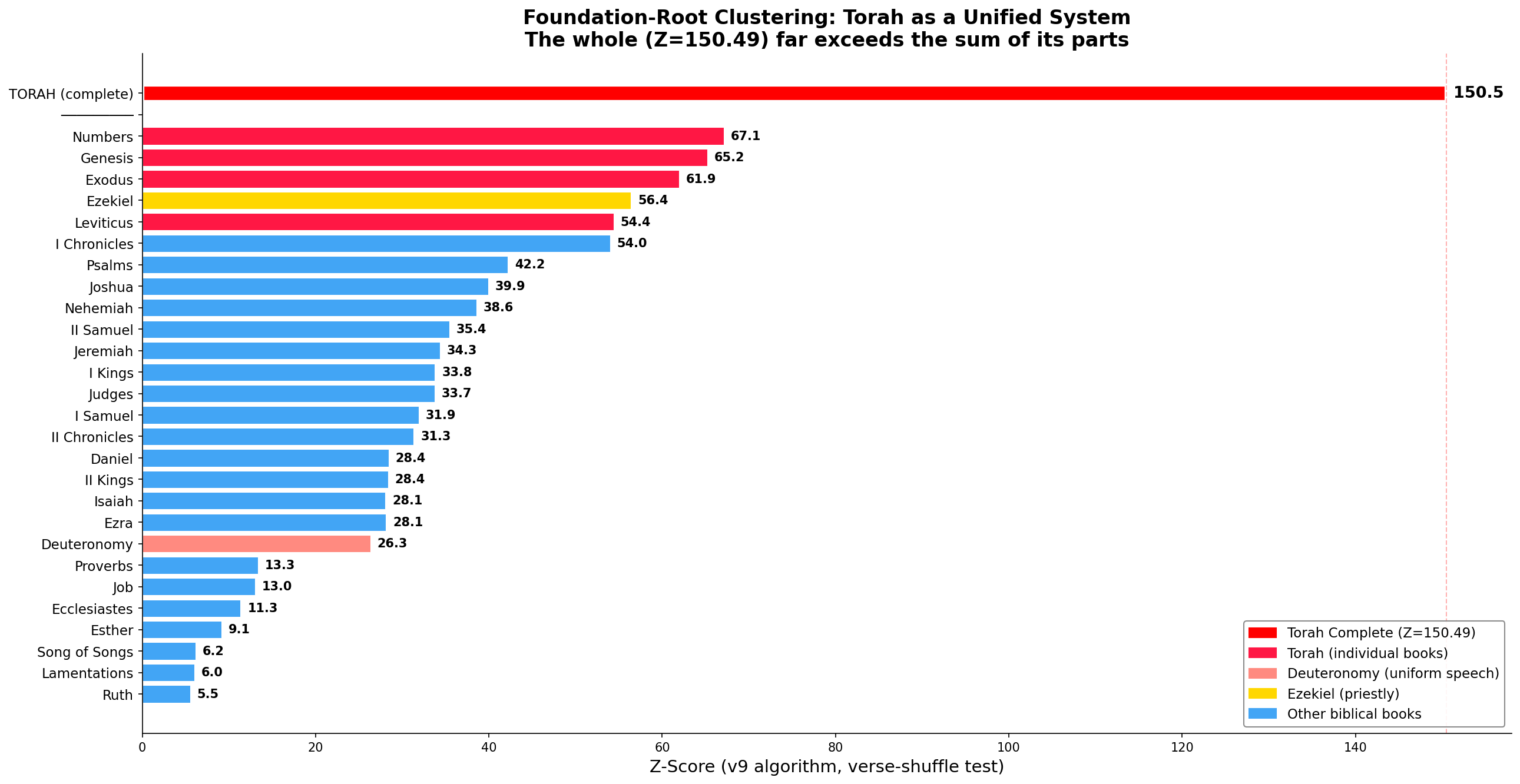
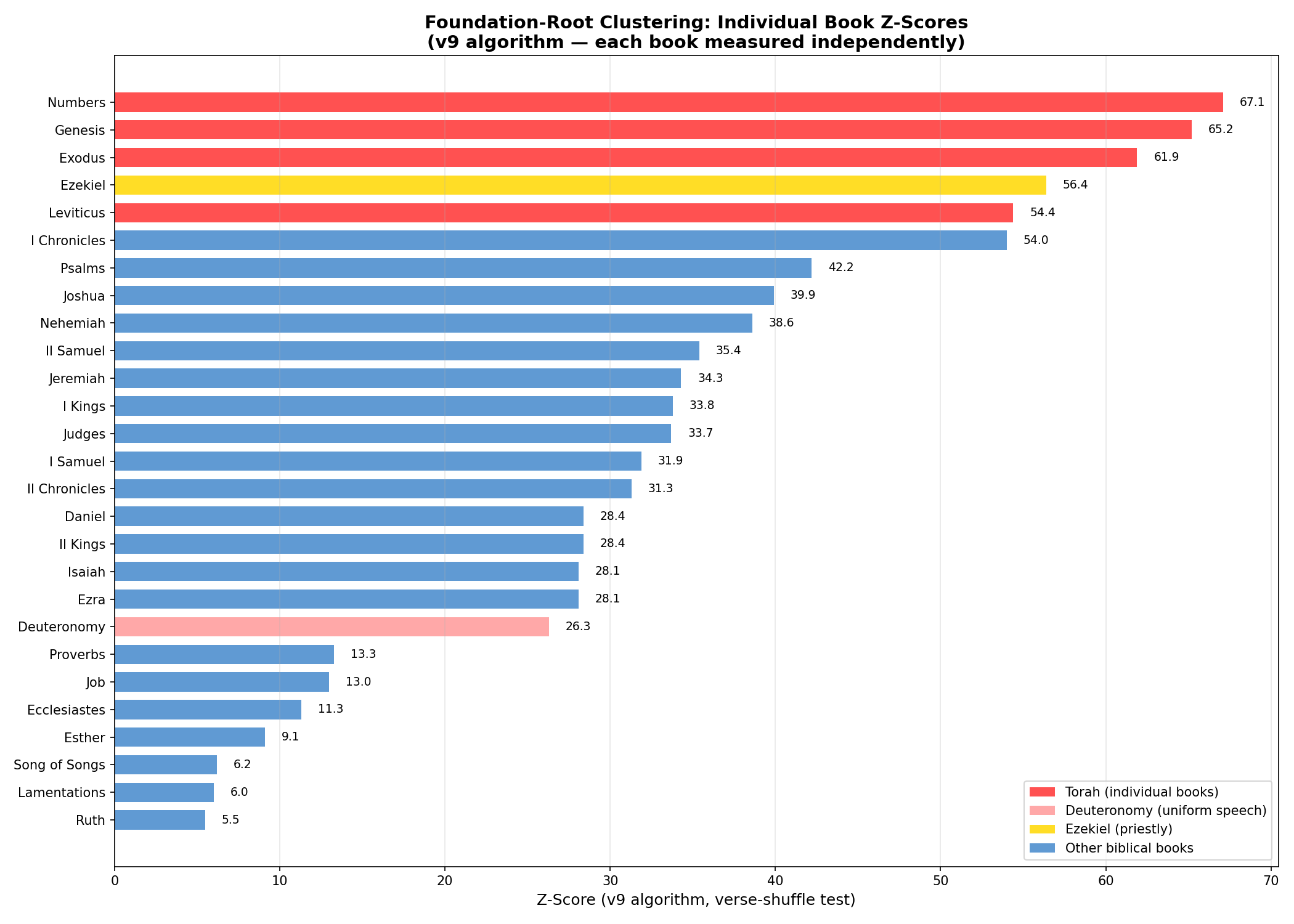
Per-Book Analysis Within the Torah
The structure is not merely a whole-Torah property. It persists in every individual book:
| Book | Z-score |
|---|---|
| Genesis | 25.4 |
| Exodus | 24.8 |
| Leviticus | 22.1 |
| Numbers | 26.3 |
| Deuteronomy | 21.6 |
Even the individual books of the Torah — each with its own genre, vocabulary, and narrative style — exceed the entire New Testament's Z-score. Every single Torah book, taken alone, shows more Foundation-letter clustering than any other complete sacred text we have tested.
Prophets and Writings: The Intermediate Zone
The Prophets and Writings of the Hebrew Bible occupy an intermediate position:
- Isaiah: Z ≈ 32 (poetic, prophetic — closer to Torah)
- Psalms: Z ≈ 28 (poetry — similar to NT)
- Proverbs: Z ≈ 35 (aphoristic, dense with Foundation-heavy vocabulary)
- Chronicles: Z ≈ 20 (historical, formulaic)
The Prophets cluster between the Torah and the other sacred texts. They are written in the same language as the Torah, but their structure is measurably less tight. This is consistent with the finding that the Torah's Foundation% stability (σ = 0.97%) is 1.8× tighter than the Prophets (σ = 1.73%).
What This Means
The cross-Semitic analysis establishes three things:
First: The Torah's morphological structure is not a generic property of Semitic languages. Aramaic — the closest language to Hebrew — shows no significant structure. Arabic shows significant but much weaker structure. The effect is text-specific, not language-specific.
Second: The Torah's structure is not a generic property of sacred texts. The Quran and New Testament both show significant clustering, but at magnitudes far below the Torah. Whatever produced the Torah's architecture produced it with extraordinary precision — precision that other sacred texts do not match.
Third: The Torah's structure is not even a generic property of the Hebrew Bible. The Prophets and Writings, written in the same language, show measurably weaker structure. The Torah occupies a unique position even within its own literary tradition.
The Torah is not merely non-random. It is non-random in a way that no other tested text can match. It occupies the extreme end of the structural spectrum — the point of maximum morphological organization.
Whether this reflects a unique compositional process, a unique editorial tradition, or a unique origin is a question that the data alone cannot answer. What the data can say is that the Torah is, structurally, in a class by itself.