Chapter 6: Structure in Raw Letters
The Frozen Base
One of the most surprising findings of this study is that the structural patterns described in the previous chapters are visible even without performing morphological analysis — without identifying individual roots or parsing individual words.
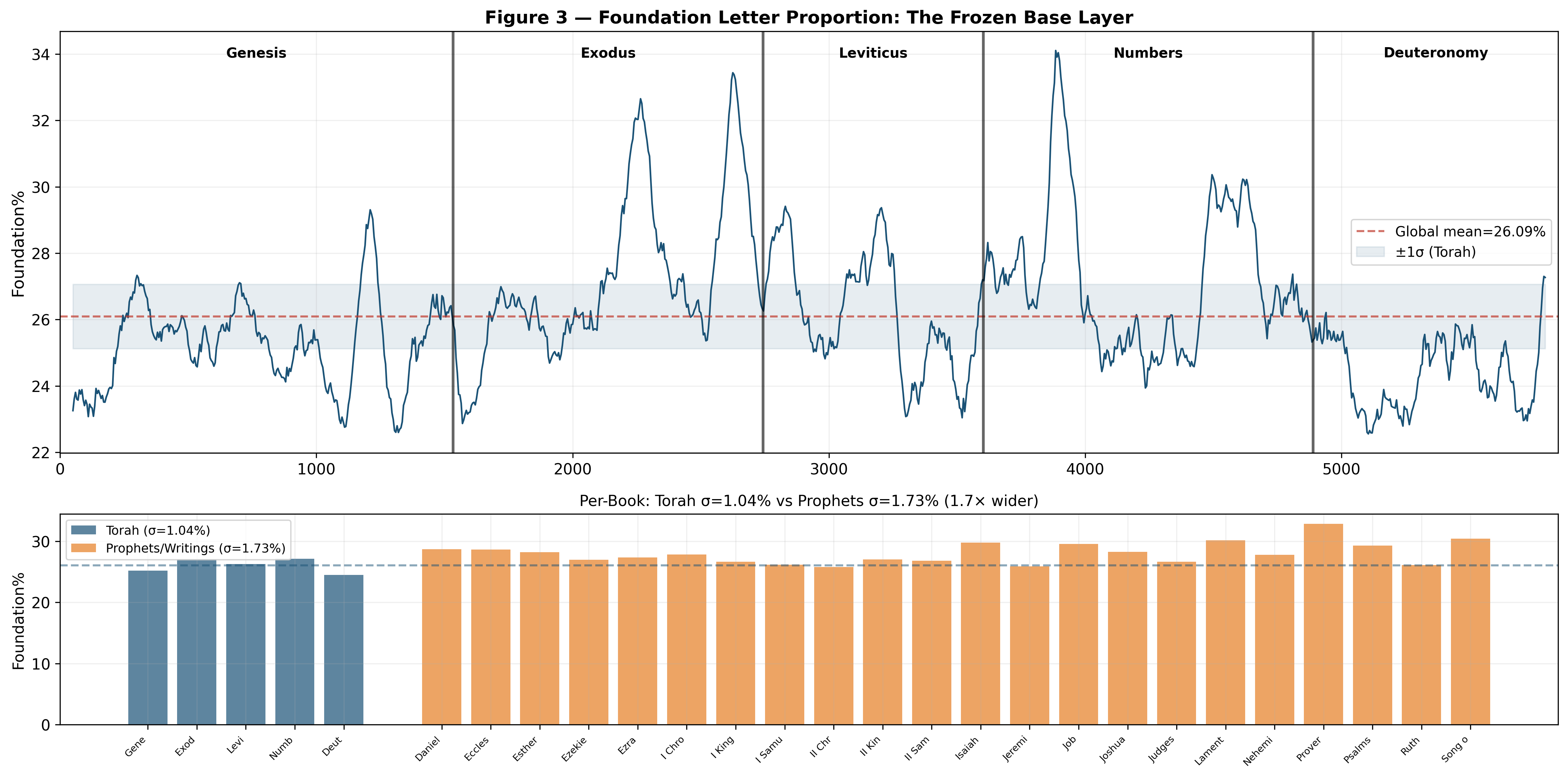
When we simply measure the proportion of Foundation letters in a given passage — what we call "Foundation%" — a remarkable property emerges: this proportion remains almost constant across the entire Torah.
The measurement is straightforward. For each book, we count every consonantal letter, classify it as Foundation or Control, and compute the ratio.
The Numbers
| Book | Verses | Foundation% | Δ from global mean |
|---|---|---|---|
| Genesis (בראשית) | 1,533 | 27.00% | −0.85% |
| Exodus (שמות) | 1,210 | 28.86% | +1.00% |
| Leviticus (ויקרא) | 859 | 27.83% | −0.02% |
| Numbers (במדבר) | 1,288 | 29.00% | +1.14% |
| Deuteronomy (דברים) | 956 | 26.57% | −1.28% |
| **Global mean** | **5,846** | **27.85%** | — |
The standard deviation across the five books is σ = 0.97%, with a total range of only 2.43 percentage points.
To appreciate how extraordinary this stability is, consider what these five books contain:
- Genesis: Creation narratives, flood story, patriarchal sagas, Joseph cycle — predominantly narrative, with some genealogy and poetry
- Exodus: Liberation narrative, plague stories, legal codes, Tabernacle construction — a mix of narrative and law
- Leviticus: Sacrificial procedures, purity regulations, dietary laws, ethical commandments — almost entirely legal/ritual
- Numbers: Census data, wilderness narratives, rebellion stories, Balaam oracles — mixed genre
- Deuteronomy: Speeches, legal recapitulation, poetry, blessings and curses — predominantly rhetorical
These are radically different types of content. Different vocabulary. Different sentence structures. Different rhetorical styles. Legal texts use different morphological constructions than narrative texts. Poetry has different word-length distributions than prose. Census data is morphologically unlike prophetic speech.
Yet the underlying proportion of Foundation letters — the morphological "base frequency" of the text — barely budges. The range is 2.43%, from Deuteronomy's 26.57% to Numbers' 29.00%.
Comparison with Prophets and Writings
How unusual is this stability? The answer becomes clear when we apply the same measurement to the rest of the Hebrew Bible.
The Prophets and Writings — a corpus of known multi-author origin, composed over several centuries — show markedly different behavior:
| Book | Foundation% |
|---|---|
| Joshua | 28.27% |
| Judges | 26.62% |
| I Samuel | 26.16% |
| II Samuel | 26.80% |
| I Kings | 27.98% |
| II Kings | 27.01% |
| Isaiah | 29.77% |
| Jeremiah | 25.91% |
| Ezekiel | 27.56% |
| Psalms | 29.28% |
| Proverbs | **32.83%** |
| Job | 29.58% |
| Song of Songs | 30.40% |
| Ruth | 26.11% |
| Lamentations | 30.15% |
| Ecclesiastes | 27.51% |
| Esther | 27.01% |
| Daniel | 27.03% |
| Ezra | 26.14% |
| Nehemiah | 27.75% |
| I Chronicles | 27.14% |
| II Chronicles | **25.77%** |
| Metric | Torah (5 books) | Prophets/Writings (22 books) | Ratio |
|---|---|---|---|
| Mean | 27.85% | 28.03% | ≈1 |
| Standard deviation | **0.97%** | **1.73%** | **1.8×** |
| Range | **2.43%** | **7.06%** | **2.9×** |
The Prophets show nearly twice the variability (1.8× in standard deviation) and nearly three times the range (2.9×). Bootstrap analysis (10,000 iterations) confirms this difference is statistically robust: the 95% confidence interval for the ratio of Prophets σ to Torah σ is [1.04, 3.83], which does not cross 1.0. In 98.3% of bootstrap samples, the Prophets standard deviation exceeds the Torah standard deviation. This is exactly what we would expect from a corpus written by many different authors over many centuries — each author's idiolect leaves a slightly different morphological imprint.
Proverbs reaches 32.83% — the highest of any book, reflecting its dense, aphoristic style heavy with root-consonant-rich vocabulary. II Chronicles drops to 25.77% — the lowest, reflecting its more formulaic, grammar-heavy prose. The spread of 7.06% in the Prophets corpus dwarfs the Torah's 2.43%.
The Torah's stability is anomalous. It is significantly tighter than what multi-authorship typically produces. This pattern is confirmed when we extend the comparison to include the Ketuvim (Writings): the 13 books of the Ketuvim show even greater variability than the Prophets, with σ=1.87% and range=7.06% — a ratio of 1.73× compared to the Torah's σ. The entire non-Torah Hebrew Bible (34 books from Prophets and Ketuvim combined) has σ=1.79% and range=7.70%, giving a ratio of 1.65× to the Torah's σ. In every comparison, the Torah is the tightest corpus — a result consistent with a single-source constraint rather than multi-authorship variation.
The Leviticus Test
Perhaps the most striking individual result involves Leviticus. This book presents a unique test case for several reasons:
1. It is almost entirely in YHWH-mode — 203 occurrences of יהוה, zero occurrences of אלהים
2. Its content is overwhelmingly legal and ritual, radically different from the narrative books that surround it
3. Its vocabulary is highly specialized — terms for sacrifices, skin diseases, bodily emissions, and purity regulations that appear nowhere else in the Torah
4. According to the Documentary Hypothesis, it is attributed to the "P" (Priestly) source — a completely different author than the "J" or "E" sources of Genesis
If different content types, divine-name modes, or authorial sources produce different Foundation% values, Leviticus should stand out dramatically. It is the book most likely to be an outlier on every criterion.
Instead, Leviticus shows the smallest deviation from the global mean of any book:
Δ = 0.02%
Two hundredths of one percent. In a book of 859 verses, containing some of the most specialized vocabulary in the Torah, the morphological base frequency matches the global average with a precision that borders on the uncanny.
This is not merely stability. This is a constraint. Something in the structure of the Torah maintains the Foundation% at a fixed value, regardless of content, genre, or mode. The morphological base is not just stable — it is locked.
Independence from Divine Names
The strongest possible objection to this finding is that it might somehow be an artifact of divine-name distribution. Perhaps the divine names, which contain only Control letters, are biasing the measurement.
To test this definitively, we performed a remove-signal experiment. Every occurrence of יהוה and אלהים in the Torah was replaced with a neutral placeholder, and all base-layer metrics were recomputed.
The results are unambiguous:
| Metric | Original Torah | Names Neutralized | Change |
|---|---|---|---|
| Foundation% scaling slope | −0.266 | −0.266 | **None** |
| Autocorrelation profile (r) | — | **0.9985** | Near-identical |
| Per-book stability (σ) | 0.985% | 0.869% | Marginal |
The Foundation% scaling slope is identical to three decimal places. The autocorrelation profile — the pattern of how Foundation% at one point predicts Foundation% at a distant point — is preserved with a correlation of 0.9985, essentially perfect.
The base layer exists completely independently of divine-name distribution. It would be there even if the Torah contained no divine names at all.
A Fractal Property
The stability we have described at the book level also appears at smaller scales. When we measure Foundation% in windows of varying sizes and compute the coefficient of variation (CV) — a normalized measure of variability — at each scale:
| Scale | Torah CV | Prophets CV |
|---|---|---|
| Per-book | 0.035 | 0.062 |
| 400 verses | 0.058 | — |
| 200 verses | 0.066 | — |
| 100 verses | 0.078 | 0.082 (est.) |
The Torah is 1.7× more uniform than the Prophets at every measured scale. This scale invariance — the same relative stability appearing at every level of magnification — is a hallmark of fractal systems.
The base layer of the Torah is not just frozen — it is frozen fractally, maintaining the same structural consistency at every scale from a hundred verses to an entire book. This property will be explored in greater depth in Chapter 10, where we examine the scaling laws that govern the Torah's statistical behavior.
Hapax Legomena: Vocabulary Independence
The Torah contains 10,329 hapax legomena — words that appear only once. Of these, 79.6% occur in verses with no divine name at all. Only 17.0% appear near YHWH and 3.4% near Elohim. The distribution of unique vocabulary is overwhelmingly independent of the divine-name mode — confirming that the base morphological layer and the mode layer operate as separate channels.
Fractal C/F Ratio
The ratio of Control letters to Foundation letters (C/F = 2.59) remains constant across all measured scales:
| Scale | Torah CV | Prophets CV |
|---|---|---|
| Per-book | 0.048 | 0.082 |
| 400 verses | 0.058 | — |
| 100 verses | 0.078 | — |
The Torah's C/F ratio is 1.7× more uniform than the Prophets at every scale. Any fragment of Torah larger than 500 letters statistically "looks like" the whole text. This self-similarity — the same ratio at every magnification — is a hallmark of fractal systems and unified composition.
What We Have Found
In these first six chapters, we have established the first half of the Torah's dual-layer architecture:
1. The 22 Hebrew letters divide into 12 Foundation and 10 Control letters
2. This division captures a fundamental morphological property (99.87% inflection dominance)
3. The partition is validated against 2.7 billion alternatives
4. The morphological engine generates ~80,000 words from ~2,000 roots
5. Foundation% remains remarkably stable across all five books (σ = 0.97%)
6. This stability is 1.8× tighter than the multi-author Prophets
7. Leviticus — the book most likely to be an outlier — deviates by only 0.02%
8. The base layer is entirely independent of divine-name distribution
9. The stability is fractal — it appears at every measured scale
This is the frozen ground. The morphological foundation of the Torah.
Now we turn to what flows above it: the river of divine names.