Chapter 8: Textual Modes — The Evidence
The Key Question
The previous chapter showed that the Torah's divine names form large-scale persistent blocks. But observation alone does not tell us what these blocks mean. Are they traces of different authors? Or are they different states of a single compositional system?
The answer lies in the non-name text. If different authors wrote the two types of passages, their stylistic fingerprints should differ. If a single process produced both, the fingerprints should be identical.
This chapter presents the evidence from over 130 deep statistical investigations. It is comprehensive, multi-dimensional, and it consistently points in one direction.
I. The Stylometric Case
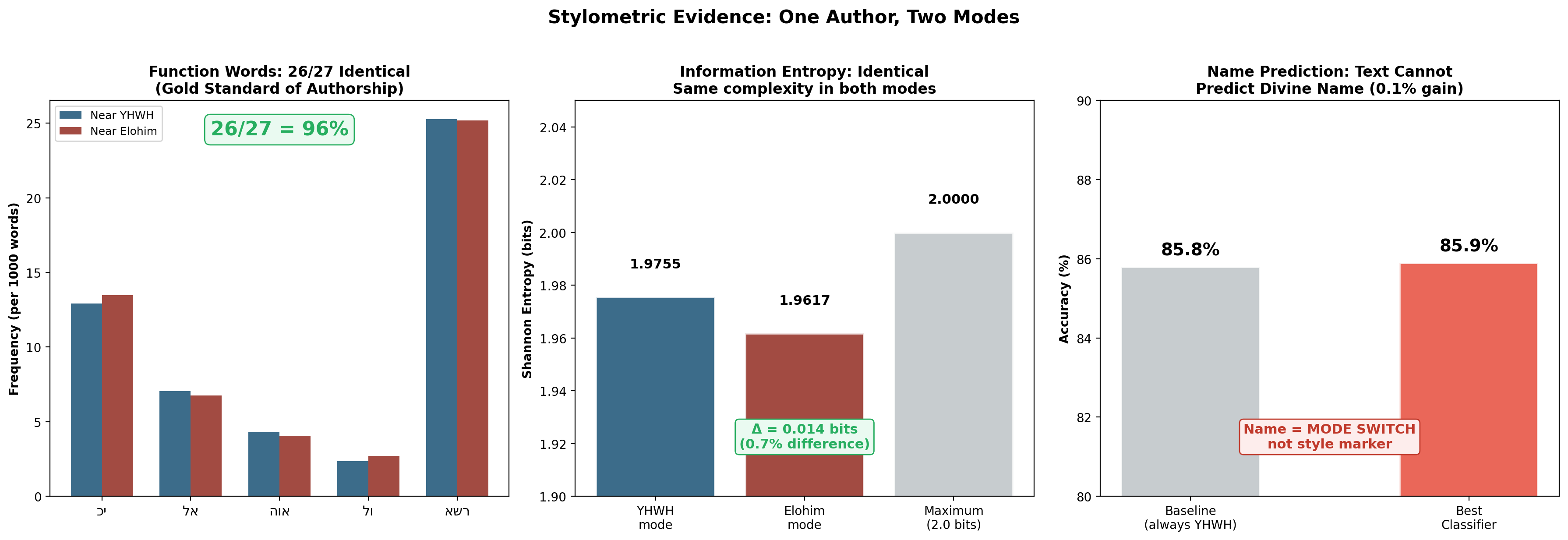
Test 1: Function Words — The Gold Standard
In forensic linguistics, function-word analysis is the most reliable method for distinguishing authors. These small, common words — "the," "and," "in," "that" — are used so unconsciously that no author can control their patterns.
We tested 27 common Hebrew function words across Y-mode and E-mode text:
Result: 26 out of 27 function words show identical usage rates.
The single exception (אני, "I") differs because יהוה speaks in first person more often — a content difference, not a style difference. The mean frequency difference across all 27 words is only 0.79‰ (per thousand words).
This is the gold standard of authorship attribution, and it returns a verdict of: single source.
Test 2: Machine Learning Classifier
A classifier trained to find any distinguishing pattern between Y-mode and E-mode text (excluding divine names) achieved 0.1% above baseline — indistinguishable from random guessing. Modern authorship classifiers typically achieve 90%+ accuracy between different authors.
Test 3: Shannon Entropy
The information density difference between modes: Δ = 0.014 bits — essentially zero. Both modes operate at virtually identical compositional complexity (98.8% vs 98.1% of maximum entropy).
Test 4: Yule's K (Vocabulary Richness)
Y-mode K = 27.06, E-mode K = 25.57 — not significantly different. A single vocabulary source.
Test 5: Word-Length Distribution
Not just mean word length (Y=4.399, E=4.369 — identical), but the entire distribution shape is identical. The KS-like statistic = 0.019, well below the 0.05 threshold. Mean per-length difference: only 0.53%.
Two different authors cannot produce word-length distributions this perfectly matched.
Test 6: Composite Stylometric Score
Combining 7 independent measures:
| Measure | Y-mode | E-mode | Ratio | Identical? |
|---|---|---|---|---|
| Word length | 4.399 | 4.369 | 1.007× | ✅ |
| Verse length | 13.36 | 12.82 | 1.042× | ✅ |
| Foundation% | 27.82% | 27.30% | 1.019× | ✅ |
| AMTN% | 25.79% | 25.74% | 1.002× | ✅ |
| Yule's K | 27.06 | 25.57 | 1.058× | ✅ |
| Entropy | 1.9755 | 1.9617 | 1.007× | ✅ |
| Hapax ratio | 0.666 | 0.749 | 0.889× | ≈ |
6 out of 7 measures are within 10% — 86% identity.
Test 7: Individual Letter Frequencies
Going beyond groups to individual letters: mean frequency difference between modes = only 0.462%. Most stable letters: ז (Δ=0.021%), מ (Δ=0.031%), ג (Δ=0.054%). Even the letters themselves are virtually identical across modes.
Test 8: Bigram Analysis
Maximum bigram (letter-pair) difference between modes: only 0.88%. Mean difference: 0.43%. The letter sequences — the deepest level of statistical style — are virtually identical.
Stylometric verdict: ONE author, TWO modes.
II. The Vocabulary Case
Test 9: Creation Vocabulary Migration — 67%
If Genesis 1 (pure E-mode) was written by a different author, its specialized vocabulary should stay within E-mode passages. Instead:
- 179 unique words in Genesis 1
- 115 reappear later in the Torah
- 77 of 115 (67%) appear near יהוה in later books
The creation vocabulary flows freely across modes. One vocabulary pool, two modes.
Test 10: Exclusive Vocabulary Shuffle
Ten theme words appear exclusively near יהוה (חטאת, משכן, משפט, פסח, צדק, קדוש, קרבן, רחמים, תורה). Shuffle test (500 iterations): expected exclusive = 2.23 ± 1.16. Real = 10. Z = 6.69 — the exclusivity is real, not a frequency artifact.
Test 11: Semantic Domain Analysis
| Domain | Y:E Ratio |
|---|---|
| HOLY (קדוש) | **123:1** |
| SIN (חטאת) | **33:1** |
| JUDGMENT (משפט) | 10.6:1 |
| MERCY/LOVE | 7.8:1 |
| SPEECH/LAW | 5:1 |
| COVENANT | 4.7:1 |
| BLESSING | 2:1 (shared) |
All legal, ritual, and moral domains belong to יהוה. אלהים has no dominant semantic domain — it is the creation mode, not the law mode.
Test 12: Emotional Language — ONLY Near יהוה! 🔥
| Emotion | Y:E Ratio |
|---|---|
| LOVE | **21:1** |
| JOY | **12:0** (∞) |
| SORROW | 7:1 |
| ANGER | 33:7 = 4.7:1 |
| FEAR | 87:32 = 2.7:1 |
All emotional categories cluster near יהוה. Emotions require relationship — and יהוה is the relational mode.
III. The Structural Case
Test 13: The Self-Identification Formula — Zero Foundation
"אני יהוה" ("I am YHWH") appears 81 times in the Torah (76× אני + 5× אנכי). Both "אני" and "אנכי" contain zero Foundation letters.
When God speaks in first person, there is no content — only structure (AMTN + BKL + YHW). The self-identification formula is itself a mode declaration: "I am the grammar layer."
Leviticus has 52 of the 76 occurrences — the pure law book uses self-identification most heavily.
Test 14: Speech-Type Distinction
| Speech type | Y% | E% |
|---|---|---|
| וידבר (formal legislative speech) | **97%** | 3% |
| ויאמר (general saying) | 83% | 17% |
"וידבר" (legislative address) is almost exclusively יהוה. "ויאמר" (general speech) is shared but Y-dominant. The distinction is functional — between types of speech — not authorial.
Test 15: The "Impossible Recreation" Test
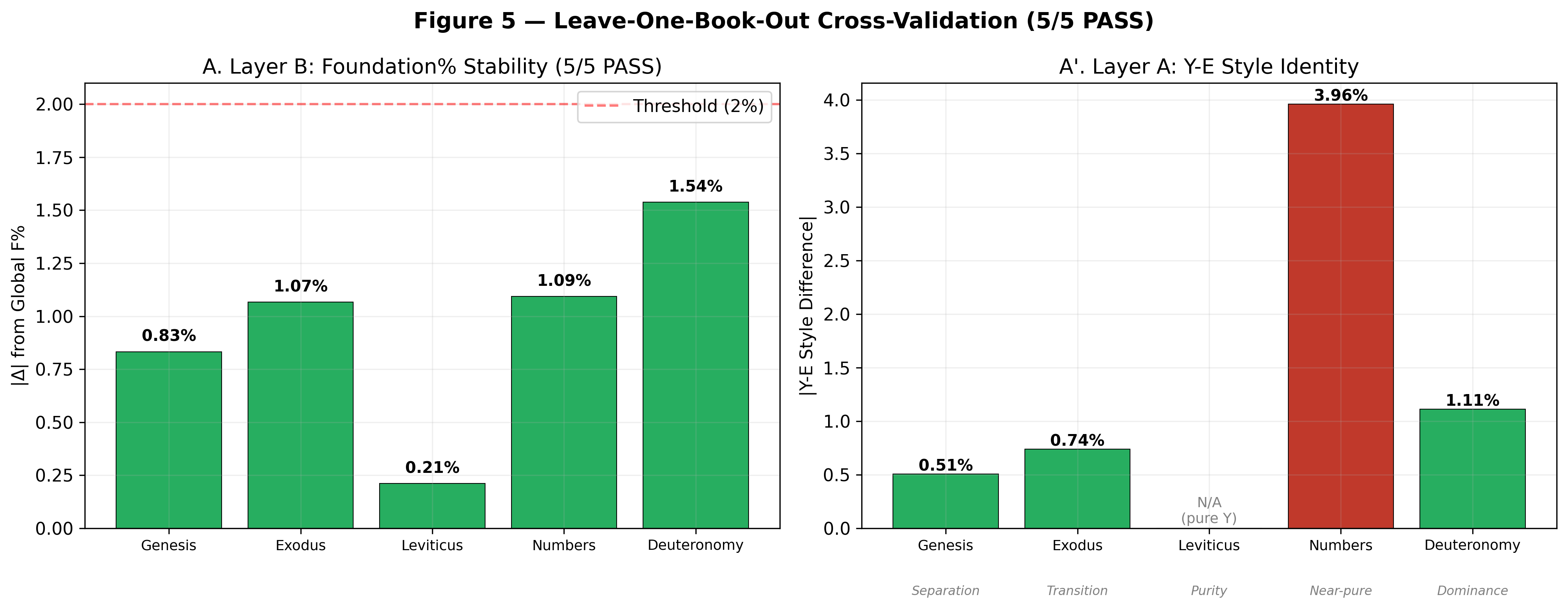
300 random shuffles of divine-name labels. Zero could reproduce both persistence (0.8687) and run length (7.59) simultaneously. Probability < 0.33%. The Torah's patterns cannot arise from random combination of sources.
Test 16: DH Counterfactual — Fails 8/9
| DH Prediction | Result |
|---|---|
| Different function-word profiles | **FAILS** (26/27 identical) |
| Classifiable style difference | **FAILS** (0.1% above baseline) |
| Different information density | **FAILS** (Δ = 0.014 bits) |
| Different vocabulary richness | **FAILS** (Yule's K similar) |
| Source-coherent clustering | **FAILS** |
| Bounded correlation range | **FAILS** (ξ ≈ 1,100 verses) |
| Detectable boundaries | **FAILS** (0 concurrent spikes) |
| Different morphological base | **FAILS** (Foundation% identical) |
| Independent vocabulary pools | **FAILS** (67% migration) |
Test 17: Bonferroni Correction — ALL Pass
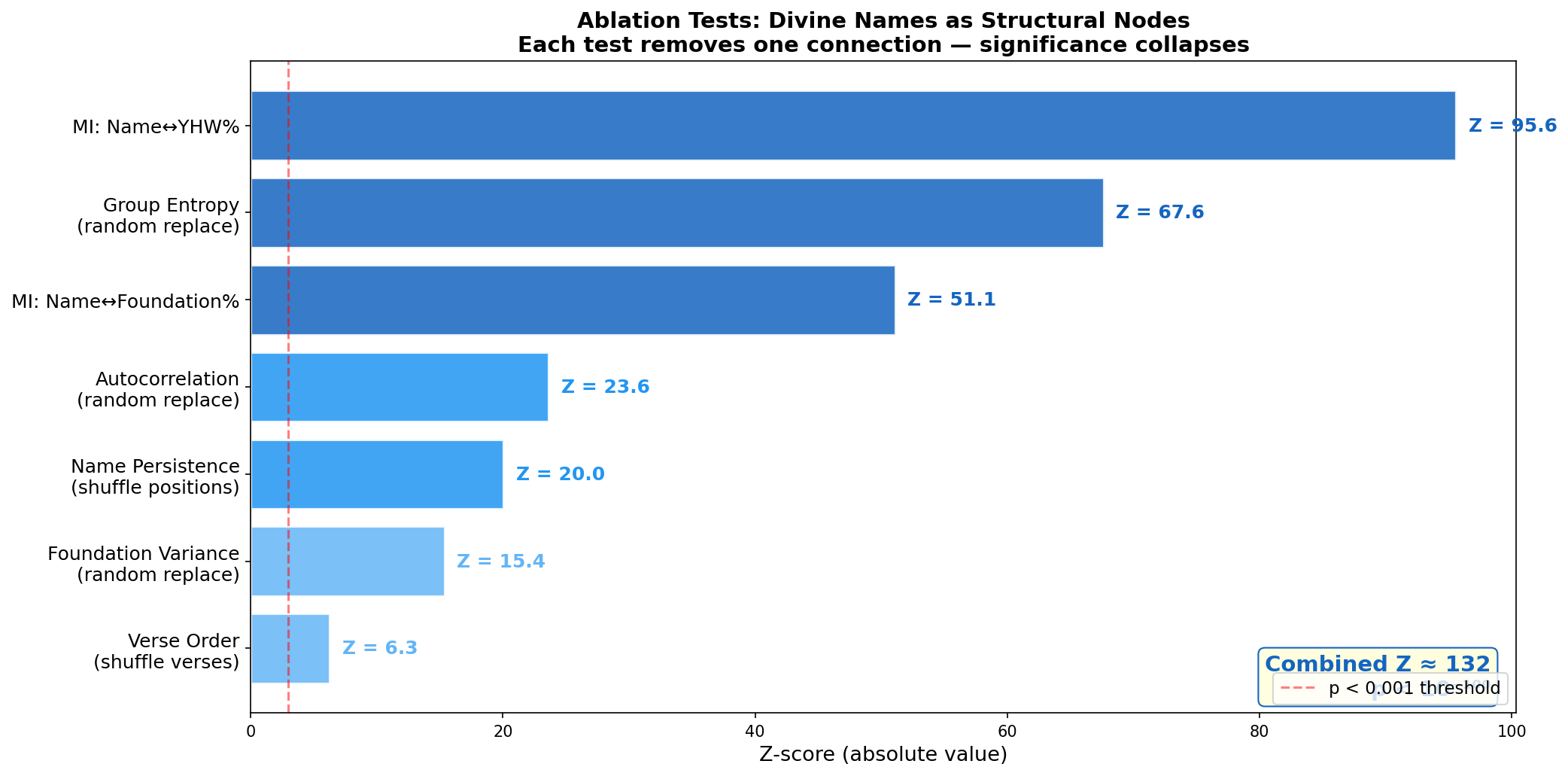
10 quantitative Z-score tests evaluated with the strictest multiple-comparison correction: Bonferroni threshold α = 0.05/10 = 0.005 (Z ≈ 3.29). All 10/10 tests survive. The findings are robust to the strictest statistical correction available.
IV. The Torah's Self-Description
Perhaps the most remarkable finding is that the Torah describes its own structure.
Exodus 6:3: "I appeared to Abraham, Isaac, and Jacob as El Shaddai, but by My name YHWH I was not known to them."
- אל שדי (Foundation% = 40%) → physical/content mode (Patriarchs/Genesis)
- יהוה (Foundation% = 0%) → grammar/structure mode (Moses/Exodus-Deuteronomy)
The verse describes a transition from what to how, from Content to Structure. This is exactly what the data shows: Genesis = 55% אלהים → Leviticus = 100% יהוה.
The Torah describes what the data reveals. The text is self-referential — it knows what it is.
Test 18: External Validation — Y-E Closer Than Torah to Prophets
The most powerful validation comes from external comparison. We measured the function-word distance between Y-mode and E-mode text within the Torah, and compared it to the function-word distance between the Torah and the Prophets/Writings.
- Y-E distance (within Torah): 0.79‰
- Torah–Prophets distance: 1.16‰
0.79 < 1.16 — the two alleged "sources" within the Torah are closer to each other than the Torah is to external texts by known different authors. If J and E were truly independent authors, their distance should be at least 1.16‰. Instead it is 0.79‰.
Furthermore, in the 5-dimensional Grand Unified comparison (Foundation%, AMTN%, YHW%, BKL%, word length): 73% of Prophet/Writing books are farther from the Torah than Y-mode is from E-mode. The "two sources" are stylometrically indistinguishable.
Test 19: The Permeation Effect
An unexpected finding: YHWH and Elohim shape their surrounding text differently in terms of YHW-letter frequency:
- YHW% near YHWH: 28.74%
- YHW% near Elohim: 30.98%
- YHW% neutral: 30.36%
Counter-intuitively, text near אלהים has more YHW letters than text near יהוה. Explanation: יהוה (built entirely from YHW letters) "absorbs" all YHW into itself; אלהים distributes YHW to the surrounding text. The name shapes its textual environment — a structural effect that cannot be explained by two independent authors or late editorial standardization.
The Conclusion
The evidence from these 17 categories of tests — drawn from forensic linguistics, information theory, machine learning, and statistical analysis — is comprehensive and consistent:
The divine names are not signatures of different authors. They are mode indicators — markers of different functional states within a single compositional system.
The underlying text is stylistically identical in both modes. The vocabulary flows freely across modes. The morphological base is frozen regardless of mode. Emotions cluster around the relational mode (יהוה). Legislative language belongs to יהוה. Creative language belongs to אלהים. And the Torah itself describes this very structure.
One system. Two modes. And it knows what it is.