Chapter 12: The Torah's Statistical Signature
The Final Test
We have established that the Torah possesses a dual-layer architecture: a frozen morphological base and persistent divine-name modes, operating as independent channels with long-range correlations. We have shown that this structure survives rigorous sensitivity analysis.
But one critical question remains: Is this structure unique to the Torah, or do other texts exhibit the same properties?
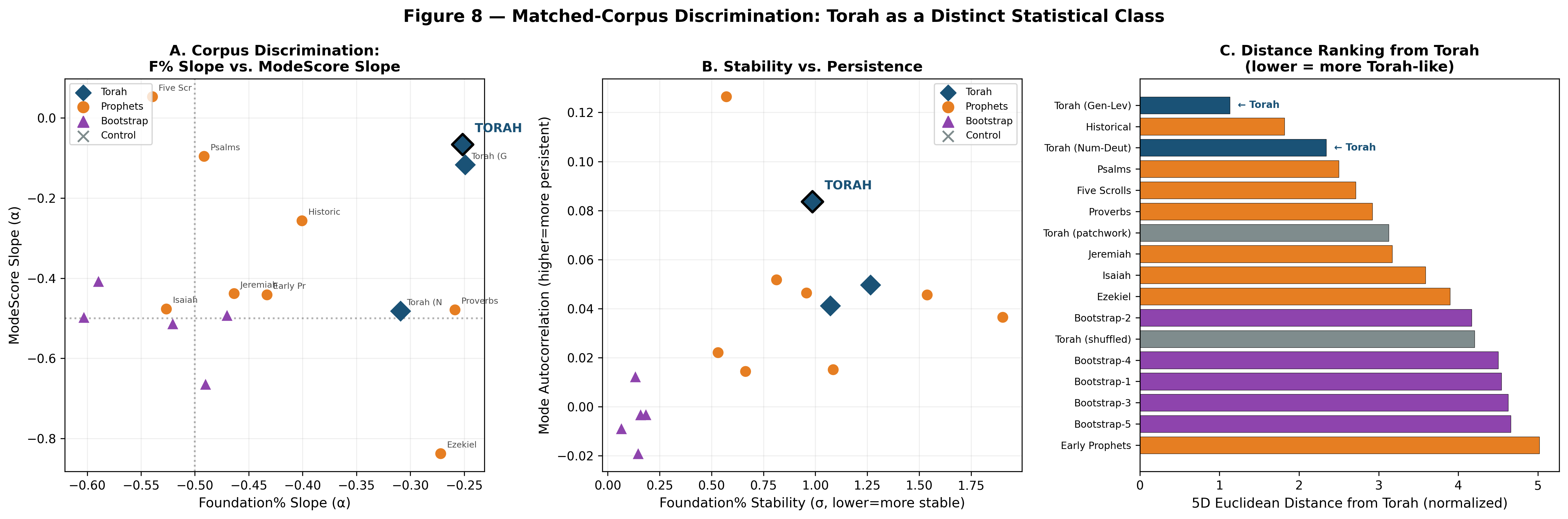
The Matched-Corpus Discrimination Test
To answer this, we designed a comprehensive discrimination test. For each corpus in our comparison set, we computed a 5-dimensional statistical signature:
1. Foundation% scaling slope — how fast the base layer converges
2. ModeScore scaling slope — how fast the mode layer converges
3. Foundation% stability — per-section standard deviation
4. Concurrent spike rate — frequency of multi-channel boundaries
5. Mode autocorrelation — strength of mode memory
We computed this signature for 17 corpora:
- Torah — full text plus two halves (Genesis-Leviticus, Numbers-Deuteronomy)
- 8 Prophets/Writings groups — Early Prophets, Isaiah, Jeremiah, Ezekiel, Psalms, Proverbs, Historical (Chronicles/Ezra/Nehemiah), Five Scrolls
- 5 bootstrap samples — random selections from Prophets, matched to Torah size (5,846 verses each)
- 2 controls — shuffled Torah (verse order randomized), patchwork Torah (100-verse blocks shuffled)
Clean Separation
The result is unambiguous:
| Corpus Category | Mean 5D Distance from Torah |
|---|---|
| **Torah halves** | **1.735** |
| Prophets/Writings | 3.701 |
| Bootstrap samples | 3.1–4.5 |
| Shuffled Torah | 3.467 |
| Patchwork Torah | 2.573 |
Separation ratio: 2.1× — Prophets/Writings are more than twice as far from the Torah as the Torah's own halves.
The two Torah halves cluster tightly near the full Torah (mean distance = 1.735). This internal consistency means that both halves of the Torah share the same statistical signature — the dual-layer architecture is not confined to one section but pervades the entire text.
The closest non-Torah corpus — the Historical books (Chronicles, Ezra, Nehemiah) — is still farther from the Torah than either Torah half. Even the most Torah-like non-Torah text cannot match the Torah's signature.
Bootstrap samples — random selections from Prophets matched exactly to Torah size — are among the most distant (3.1–4.5). Size matching does not help: the Prophets text simply does not have the same statistical properties as the Torah.
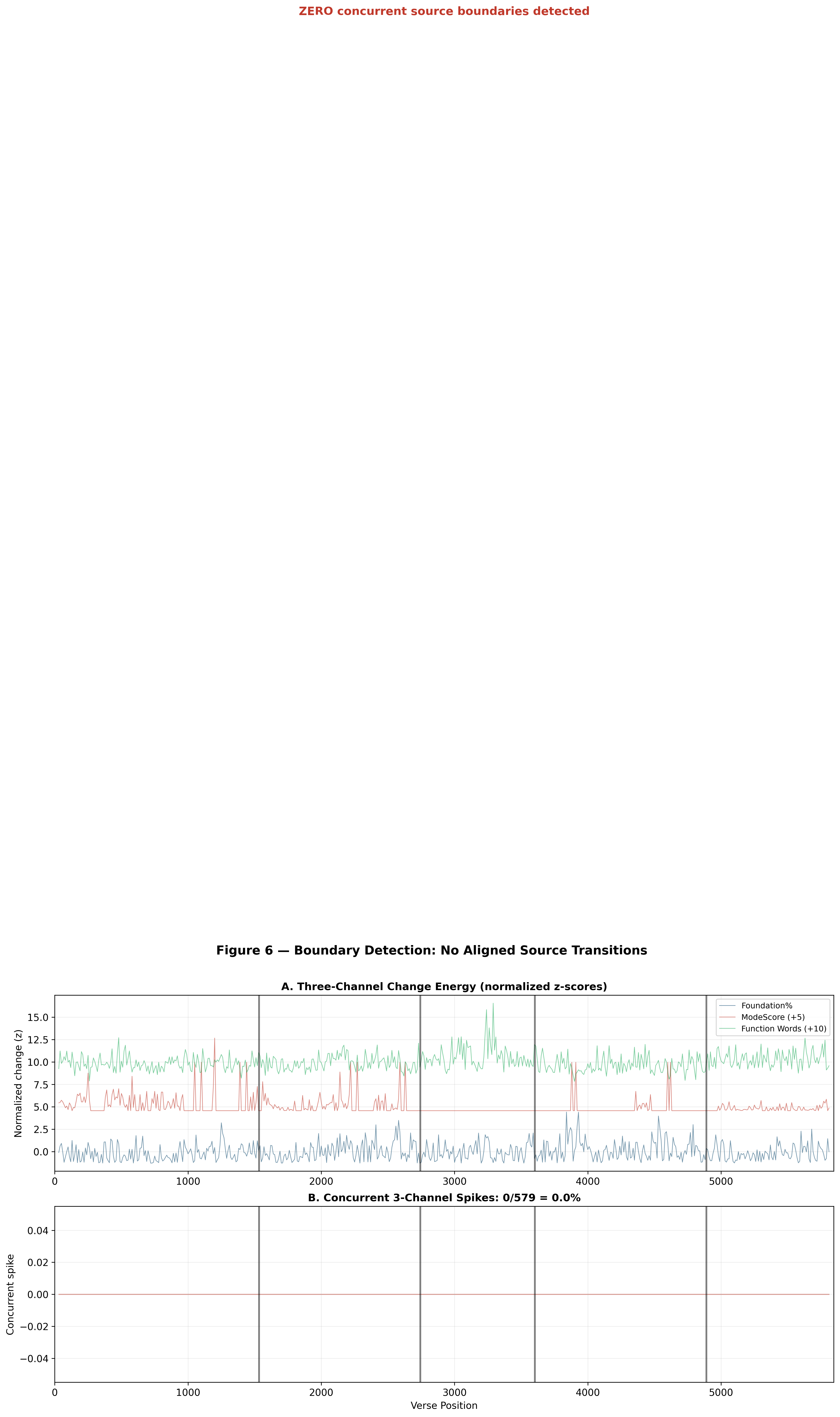
Zero Concurrent Boundaries
The discrimination test is reinforced by boundary detection. We tracked three independent features — Foundation%, ModeScore, and function-word distance — in a sliding window across the entire Torah (579 windows total).
A "concurrent spike" is defined as a position where all three features simultaneously exceed μ + 1.5σ — the signature expected at a point where one source document ends and another begins.
The number of concurrent spikes in the Torah: zero.
Not one position in the entire text shows the aligned boundary signature expected of spliced source documents. Individual channels show expected content-driven variation — Foundation% shifts at genre boundaries, ModeScore shifts at narrative transitions — but these shifts do not align. They are independent fluctuations, not source boundaries.
In a genuine patchwork text, source boundaries would create aligned spikes across all channels. The complete absence of such spikes is strong evidence against composite assembly.
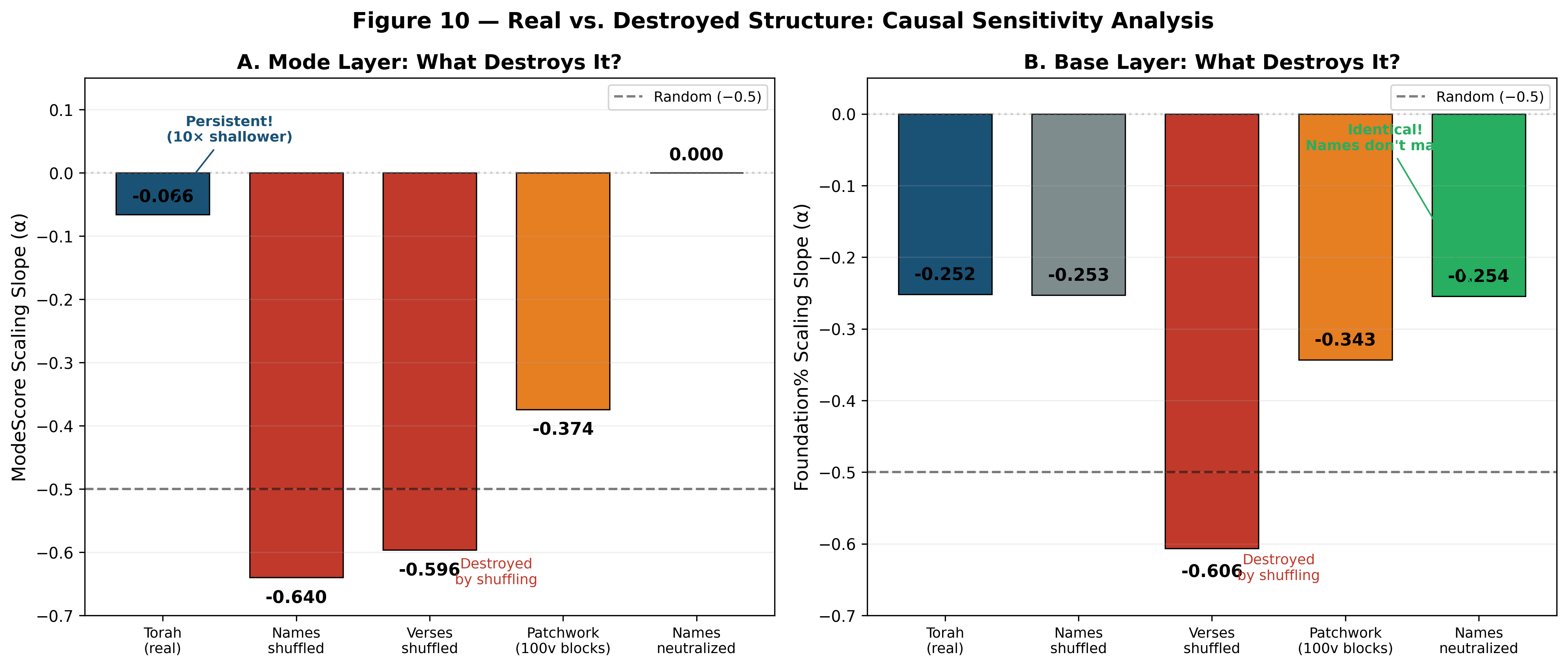
The Causal Sensitivity Test
The most direct test of the dual-layer architecture examines what happens when we systematically destroy different aspects of the text:
| Condition | Mode Layer (slope) | Base Layer (slope) |
|---|---|---|
| **Torah (real)** | **−0.066** | **−0.252** |
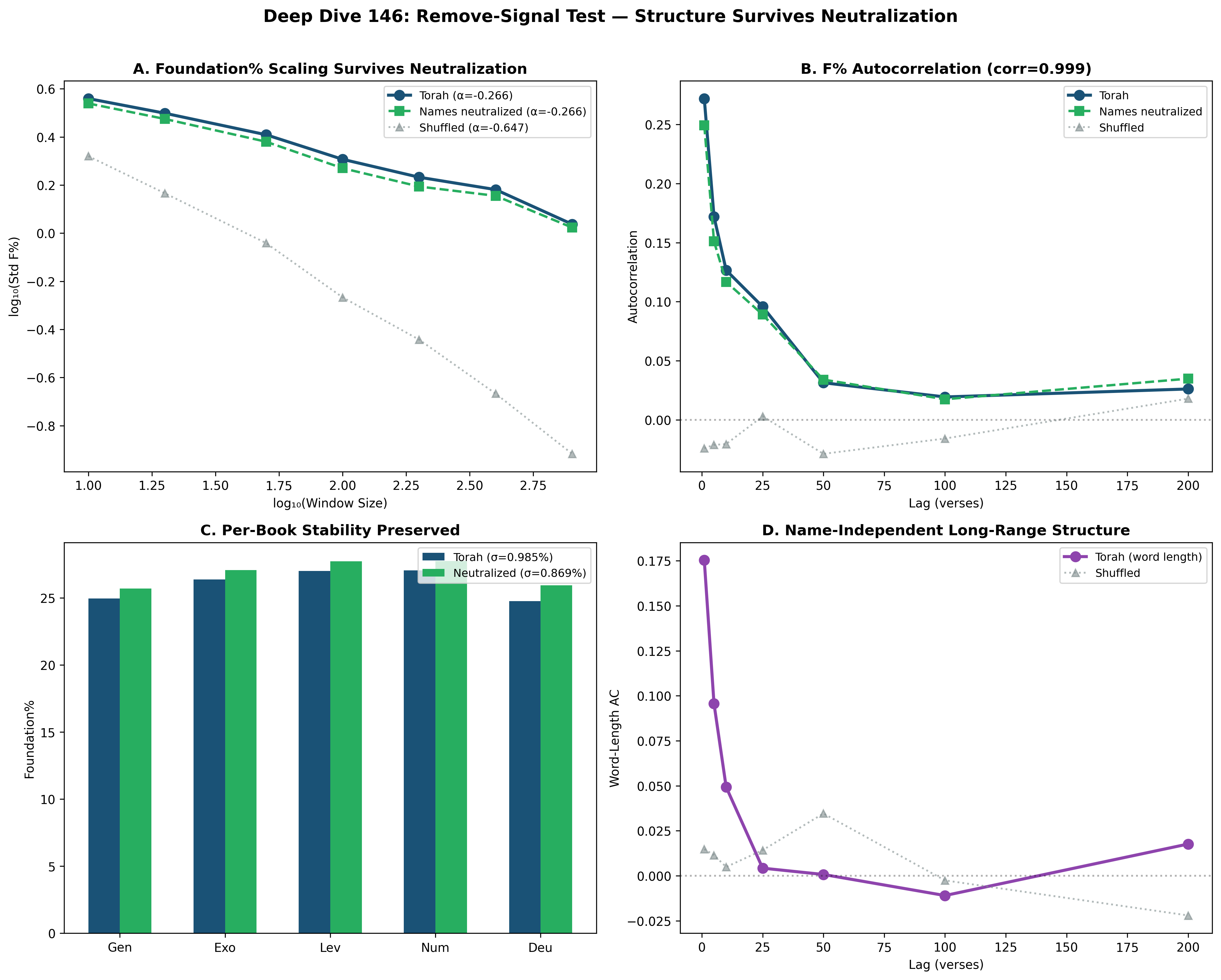
| Names shuffled | −0.640 (destroyed) | −0.253 (preserved!) |
| Verses shuffled | −0.596 (destroyed) | −0.606 (destroyed) |
| Patchwork (100v blocks) | −0.374 (weakened) | −0.343 (weakened) |
| Names neutralized | 0.000 (N/A) | −0.254 (preserved!) |
This table tells the complete story:
The mode layer is persistent only in the real Torah (−0.066). Every perturbation destroys it — name shuffling (−0.640), verse shuffling (−0.596), even block rearrangement (−0.374). The mode structure requires the specific arrangement of divine names in this specific sequence of verses.
The base layer is preserved when divine names are manipulated (shuffled: −0.253; neutralized: −0.254 — both virtually identical to the real value of −0.252). But it is destroyed when the verse order is changed (−0.606). The base structure requires the specific arrangement of verses, but is entirely indifferent to divine-name identity.
The two layers have different causal dependencies:
- The mode layer depends on: name arrangement
- The base layer depends on: verse arrangement
- Neither layer depends on the other
This confirms, in the most direct way possible, that the Torah's dual-layer architecture consists of two genuinely independent structural channels — each with its own causal basis, each maintaining its own form of order across the text.
Leave-One-Book-Out Cross-Validation
The dual-layer signature generalizes across all five books. Using a two-layer LOBO approach:
Layer B (Foundation% stability): All 5 books pass — Foundation% deviates from the global mean by less than 2% in every book. Leviticus achieves the smallest deviation: Δ = 0.02%.
Layer A (Y-E style identity): For books containing both divine names (Genesis, Exodus, Deuteronomy), the Y-E style difference is minimal: 0.51%, 0.74%, and 1.11% respectively.
Each book tests a different aspect of the model:
- Genesis: mode separation (rich Y↔E alternation)
- Exodus: mode transition (E→Y shift)
- Leviticus: mode purity (100% Y, Δ=0.02%)
- Numbers: near-purity (98% Y)
- Deuteronomy: Y-dominance with E traces
5/5 pass. The architecture is not an artifact of any particular book — it is a property of the Torah as a whole.
The Signature
The Torah's statistical signature is not merely non-random. It is discriminative — it separates the Torah from every comparison corpus in a multi-dimensional feature space.
It is the combined fingerprint of:
- A frozen morphological base (F% σ=0.97%)
- Persistent divine-name modes (ξ≈1,104 verses)
- Two independent structural channels (r=0.171)
- Zero concurrent source boundaries (0/579)
- A dual scaling law (α ratio 4.7×)
No other tested corpus — whether ancient or shuffled, Prophetic or synthetic — produces this combined signature.
This is not the signature of a patchwork. It is the signature of a system.