פרק 8: אופני הטקסט — העדויות
השאלה המרכזית
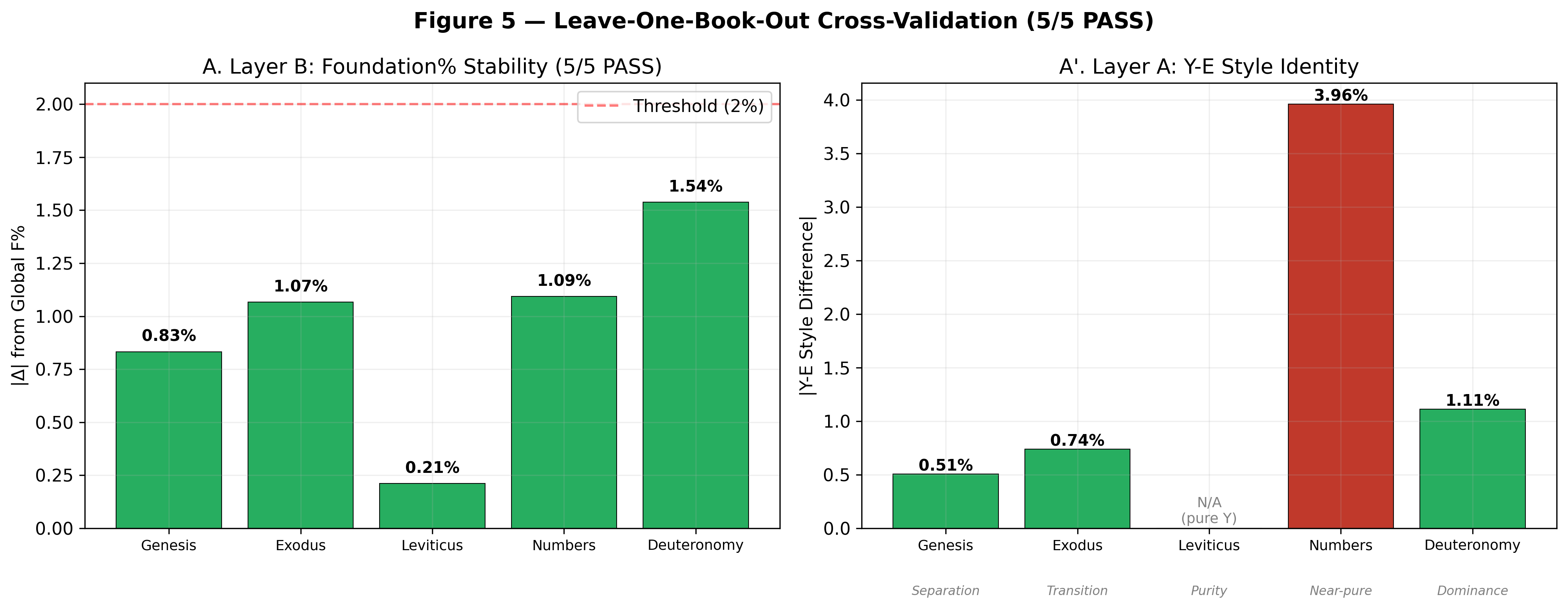
הפרק הקודם הראה כי השמות האלוהיים בתורה יוצרים גושים מתמשכים בקנה מידה גדול. אך התבוננות בלבד אינה מגלה לנו מה פירוש הגושים הללו. האם הם עקבות של מחברים שונים? או שמא הם מצבים שונים של מערכת חיבור יחידה?
התשובה טמונה בטקסט שאינו שמות. אם מחברים שונים כתבו את שני סוגי הקטעים, טביעות האצבע הסגנוניות שלהם צריכות להיות שונות. אם תהליך יחיד הוליד את שניהם, טביעות האצבע צריכות להיות זהות.
פרק זה מציג את העדויות מלמעלה מ-130 חקירות סטטיסטיות עמוקות. הן מקיפות, רב-ממדיות, והן מצביעות באופן עקבי לכיוון אחד.
א. המקרה הסטילומטרי
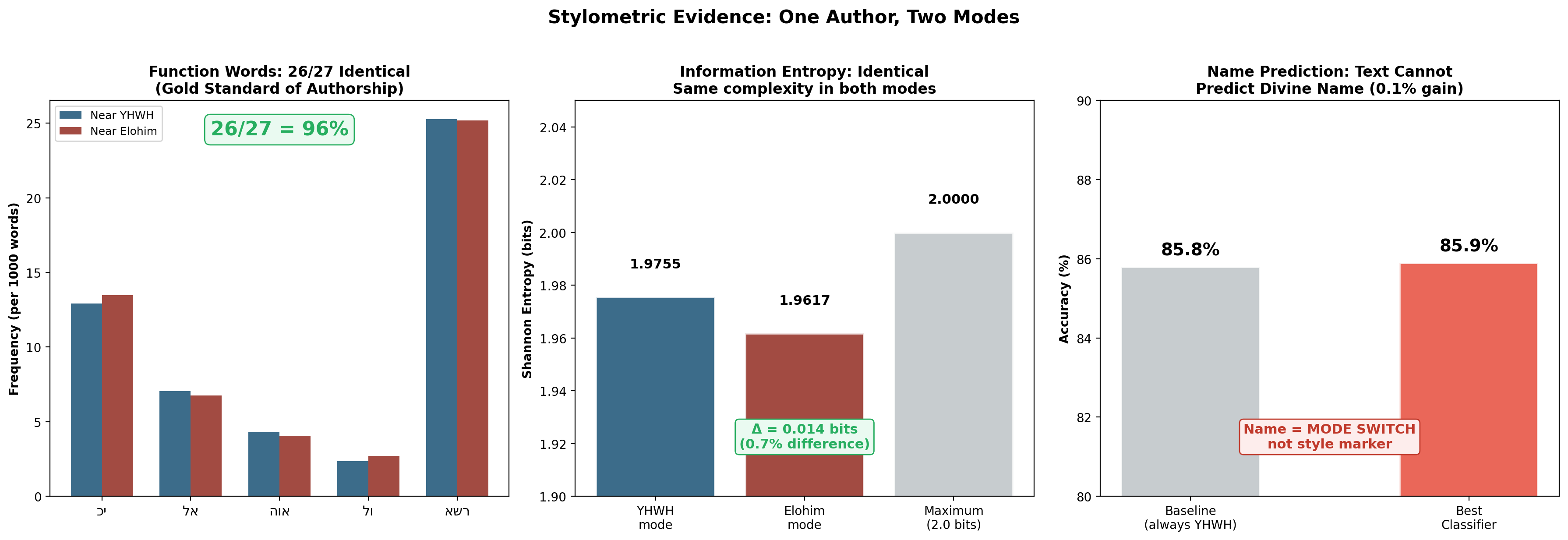
מבחן 1: מילות יחס — תקן הזהב
בבלשנות משפטית, ניתוח מילות יחס הוא השיטה האמינה ביותר להבחנה בין מחברים. המילים הקטנות והנפוצות הללו — "את", "ו", "ב", "כי" — נעשות בהן שימוש באופן כה לא מודע עד שאף מחבר אינו יכול לשלוט בדפוסיהן.
בדקנו 27 מילות יחס עבריות נפוצות על פני טקסט Y-mode ו-E-mode:
תוצאה: 26 מתוך 27 מילות יחס מראות שיעורי שימוש זהים.
החריג היחיד (אני) שונה משום שיהוה מדבר בגוף ראשון לעתים קרובות יותר — הבדל תוכן, לא הבדל סגנון. הפרש התדירות הממוצע על פני כל 27 המילים הוא רק 0.79‰ (לאלף מילים).
זהו תקן הזהב של ייחוס מחברות, והוא מחזיר פסק דין של: מקור יחיד.
מבחן 2: מסווג למידת מכונה
מסווג שאומן למצוא כל דפוס מבחין בין טקסט Y-mode ו-E-mode (למעט שמות אלוהיים) השיג 0.1% מעל קו הבסיס — בלתי ניתן להבחנה מניחוש אקראי. מסווגי מחברות מודרניים בדרך כלל משיגים דיוק של 90%+ בין מחברים שונים.
מבחן 3: אנטרופיית שאנון
הפרש צפיפות המידע בין האופנים: Δ = 0.014 ביטים — למעשה אפס. שני האופנים פועלים במורכבות חיבור זהה כמעט (98.8% לעומת 98.1% מהאנטרופיה המקסימלית).
מבחן 4: K של יול (עושר אוצר המילים)
Y-mode K = 27.06, E-mode K = 25.57 — לא שונה באופן משמעותי. מקור אוצר מילים יחיד.
מבחן 5: התפלגות אורך מילים
לא רק אורך מילה ממוצע (Y=4.399, E=4.369 — זהה), אלא צורת ההתפלגות כולה זהה. הסטטיסטיקה דמוית-KS = 0.019, הרבה מתחת לסף 0.05. הפרש ממוצע לפי אורך: רק 0.53%.
שני מחברים שונים אינם יכולים לייצר התפלגויות אורך מילים תואמות בצורה כה מושלמת.
מבחן 6: ציון סטילומטרי מורכב
שילוב 7 מדדים עצמאיים:
| מדד | Y-mode | E-mode | יחס | זהה? |
|---|---|---|---|---|
| אורך מילה | 4.399 | 4.369 | 1.007× | ✅ |
| אורך פסוק | 13.36 | 12.82 | 1.042× | ✅ |
| יסוד% | 27.82% | 27.30% | 1.019× | ✅ |
| AMTN% | 25.79% | 25.74% | 1.002× | ✅ |
| K של יול | 27.06 | 25.57 | 1.058× | ✅ |
| אנטרופיה | 1.9755 | 1.9617 | 1.007× | ✅ |
| יחס הפקס | 0.666 | 0.749 | 0.889× | ≈ |
6 מתוך 7 מדדים נמצאים בטווח של 10% — 86% זהות.
מבחן 7: תדירויות אותיות בודדות
מעבר לקבוצות לאותיות בודדות: הפרש תדירות ממוצע בין האופנים = רק 0.462%. האותיות היציבות ביותר: ז (Δ=0.021%), מ (Δ=0.031%), ג (Δ=0.054%). אפילו האותיות עצמן זהות כמעט על פני האופנים.
מבחן 8: ניתוח ביגרמות
הפרש ביגרמות (זוגות אותיות) מקסימלי בין האופנים: רק 0.88%. הפרש ממוצע: 0.43%. רצפי האותיות — הרמה העמוקה ביותר של סגנון סטטיסטי — זהים כמעט.
פסק דין סטילומטרי: מחבר אחד, שני אופנים.
ב. המקרה האוצר-מיליוני
מבחן 9: נדידת אוצר מילים הבריאה — 67%
אם בראשית א (E-mode טהור) נכתב על ידי מחבר אחר, אוצר המילים המיוחד שלו צריך להישאר בתוך קטעי E-mode. במקום זאת:
- 179 מילים ייחודיות בבראשית א
- 115 מופיעות שוב מאוחר יותר בתורה
- 77 מתוך 115 (67%) מופיעות ליד יהוה בספרים מאוחרים יותר
אוצר מילים הבריאה זורם בחופשיות על פני האופנים. מאגר אוצר מילים אחד, שני אופנים.
מבחן 10: ערבוב אוצר מילים בלעדי
עשר מילות נושא מופיעות באופן בלעדי ליד יהוה (חטאת, משכן, משפט, פסח, צדק, קדוש, קרבן, רחמים, תורה). מבחן ערבוב (500 איטרציות): בלעדיות צפויה = 2.23 ± 1.16. אמיתי = 10. Z = 6.69 — הבלעדיות אמיתית, לא חפץ תדירות.
מבחן 11: ניתוח תחומים סמנטיים
| תחום | יחס Y:E |
|---|---|
| קדוש | **123:1** |
| חטא (חטאת) | **33:1** |
| משפט | 10.6:1 |
| רחמים/אהבה | 7.8:1 |
| דיבור/תורה | 5:1 |
| ברית | 4.7:1 |
| ברכה | 2:1 (משותף) |
כל התחומים המשפטיים, הפולחניים והמוסריים שייכים ליהוה. לאלהים אין תחום סמנטי דומיננטי — הוא אופן הבריאה, לא אופן החוק.
מבחן 12: שפה רגשית — רק ליד יהוה! 🔥
| רגש | יחס Y:E |
|---|---|
| אהבה | **21:1** |
| שמחה | **12:0** (∞) |
| עצב | 7:1 |
| כעס | 33:7 = 4.7:1 |
| פחד | 87:32 = 2.7:1 |
כל הקטגוריות הרגשיות מתקבצות ליד יהוה. רגשות דורשים יחסים — ויהוה הוא האופן היחסי.
ג. המקרה המבני
מבחן 13: נוסחת הזיהוי העצמי — יסוד אפס
"אני יהוה" מופיע 81 פעמים בתורה (76× אני + 5× אנכי). גם "אני" וגם "אנכי" מכילים אפס אותיות יסוד.
כשאלוהים מדבר בגוף ראשון, אין תוכן — רק מבנה (AMTN + BKL + YHW). נוסחת הזיהוי העצמי היא עצמה הכרזת אופן: "אני שכבת הדקדוק."
בויקרא יש 52 מתוך 76 המופעים — ספר החוק הטהור משתמש בזיהוי עצמי בכבדות הגדולה ביותר.
מבחן 14: הבחנת סוגי דיבור
| סוג דיבור | Y% | E% |
|---|---|---|
| וידבר (דיבור חקיקתי פורמלי) | **97%** | 3% |
| ויאמר (אמירה כללית) | 83% | 17% |
"וידבר" (פנייה חקיקתית) הוא כמעט באופן בלעדי יהוה. "ויאמר" (דיבור כללי) משותף אך Y-דומיננטי. ההבחנה היא פונקציונלית — בין סוגי דיבור — לא מחברית.
מבחן 15: מבחן "השחזור הבלתי אפשרי"
300 ערבובים אקראיים של תוויות שמות אלוהיים. אפס יכלו לשחזר גם התמדה (0.8687) וגם אורך ריצה (7.59) בו-זמנית. הסתברות < 0.33%. הדפוסים של התורה אינם יכולים לנבוע משילוב אקראי של מקורות.
מבחן 16: הנגדי DH — נכשל 8/9
| תחזית DH | תוצאה |
|---|---|
| פרופילי מילות יחס שונים | **נכשל** (26/27 זהים) |
| הבדל סגנון ניתן לסיווג | **נכשל** (0.1% מעל בסיס) |
| צפיפות מידע שונה | **נכשל** (Δ = 0.014 ביטים) |
| עושר אוצר מילים שונה | **נכשל** (K של יול דומה) |
| התקבצות קוהרנטית-מקור | **נכשל** |
| טווח קורלציה מוגבל | **נכשל** (ξ ≈ 1,100 פסוקים) |
| גבולות ניתנים לזיהוי | **נכשל** (0 שיאים בו-זמניים) |
| בסיס מורפולוגי שונה | **נכשל** (יסוד% זהה) |
| מאגרי אוצר מילים עצמאיים | **נכשל** (67% נדידה) |
מבחן 17: תיקון בונפרוני — הכל עובר
10 מבחני Z-score כמותיים הוערכו עם התיקון המחמיר ביותר להשוואות מרובות: סף בונפרוני α = 0.05/10 = 0.005 (Z ≈ 3.29). כל 10/10 המבחנים שורדים. הממצאים עמידים לתיקון הסטטיסטי המחמיר ביותר הזמין.
ד. התיאור העצמי של התורה
אולי הממצא המדהים ביותר הוא שהתורה מתארת את המבנה שלה עצמה.
שמות ו:ג: "ואל אברהם אל יצחק ואל יעקב נראיתי באל שדי ושמי יהוה לא נודעתי להם."
- אל שדי (יסוד% = 40%) → אופן פיזי/תוכן (אבות/בראשית)
- יהוה (יסוד% = 0%) → אופן דקדוק/מבנה (משה/שמות-דברים)
הפסוק מתאר מעבר ממה לאיך, מתוכן למבנה. זה בדיוק מה שהנתונים מראים: בראשית = 55% אלהים → ויקרא = 100% יהוה.
התורה מתארת מה שהנתונים חושפים. הטקסט הוא מתייחס לעצמו — הוא יודע מה הוא.
מבחן 18: אימות חיצוני — Y-E קרובים יותר מהתורה לנביאים
האימות החזק ביותר בא מהשוואה חיצונית. מדדנו את המרחק של מילות יחס בין טקסט Y-mode ו-E-mode בתוך התורה, והשווינו אותו למרחק מילות יחס בין התורה לנביאים/כתובים.
- מרחק Y-E (בתוך התורה): 0.79‰
- מרחק תורה–נביאים: 1.16‰
0.79 < 1.16 — שני ה"מקורות" הנטענים בתוך התורה קרובים יותר זה לזה מאשר התורה לטקסטים חיצוניים של מחברים שונים ידועים. אם J ו-E היו באמת מחברים עצמאיים, המרחק שלהם צריך להיות לפחות 1.16‰. במקום זאת הוא 0.79‰.
יתר על כן, בהשוואה המאוחדת הגדולה ה-5-ממדית (יסוד%, AMTN%, YHW%, BKL%, אורך מילה): 73% מספרי נביאים/כתובים רחוקים יותר מהתורה מאשר Y-mode מ-E-mode. ה"שני מקורות" בלתי ניתנים להבחנה סטילומטרית.
מבחן 19: אפקט החדירה
ממצא בלתי צפוי: יהוה ואלהים מעצבים את הטקסט הסובב אותם באופן שונה מבחינת תדירות אותיות YHW:
- YHW% ליד יהוה: 28.74%
- YHW% ליד אלהים: 30.98%
- YHW% נייטרלי: 30.36%
באופן נוגד אינטואיציה, לטקסט ליד אלהים יש יותר אותיות YHW מאשר לטקסט ליד יהוה. הסבר: יהוה (הבנוי כולו מאותיות YHW) "סופג" את כל ה-YHW לתוכו; אלהים מפזר YHW לטקסט הסובב. השם מעצב את הסביבה הטקסטואלית שלו — אפקט מבני שאינו יכול להיות מוסבר על ידי שני מחברים עצמאיים או תקנון עריכתי מאוחר.
המסקנה
העדויות מ-17 הקטגוריות הללו של מבחנים — הנלקחות מבלשנות משפטית, תורת המידע, למידת מכונה וניתוח סטטיסטי — הן מקיפות ועקביות:
השמות האלוהיים אינם חתימות של מחברים שונים. הם מחווני אופן — סמנים של מצבים פונקציונליים שונים בתוך מערכת חיבור יחידה.
הטקסט הבסיסי זהה סגנונית בשני האופנים. אוצר המילים זורם בחופשיות על פני האופנים. הבסיס המורפולוגי קפוא ללא קשר לאופן. רגשות מתקבצים סביב האופן היחסי (יהוה). שפה חקיקתית שייכת ליהוה. שפה יוצרת שייכת לאלהים. והתורה עצמה מתארת את המבנה הזה בדיוק.
מערכת אחת. שני אופנים. והיא יודעת מה היא.